
En este análisis exploraremos las causas del fallo en la red de Cloudflare que impidió usar ChatGPT, X y otros programas, un incidente que dejó sin servicio a múltiples plataformas durante más de dos horas. Profundizaremos en qué falló a nivel técnico, por qué muchos servicios dependientes se vieron afectados y qué lecciones podemos extraer sobre la dependencia de infraestructuras centralizadas. Este episodio no solo evidencia la fragilidad de algunas arquitecturas modernas, sino que también nos invita a repensar cómo diseñamos sistemas resilientes.

Tabla de Contenido

Causas técnicas del fallo en la red de Cloudflare
¿Qué provocó el incidente en la red de Cloudflare?
Uno de los principales desencadenantes del problema fue un pico de tráfico inusual (“unusual traffic spike”) detectado por Cloudflare. Según la empresa, algunos flujos de datos en su red se saturaron, lo que causó errores internos.
Este aumento repentino no fue identificado inmediatamente como un ataque, sino más bien como una carga que excedió lo que ciertos servicios podían manejar de manera normal.

Dependencia crítica: el papel de Workers KV
Un punto central del fallo estuvo en el servicio Workers KV de Cloudflare. Este componente es un almacén clave-valor distribuido, usado por múltiples productos internos: autenticación, configuración, entrega de recursos, etc.
Durante el incidente, aproximadamente el 90 % de las solicitudes a Workers KV fallaron, especialmente aquellas que no estaban en caché.
Esta falla tuvo un efecto dominó: muchos servicios esenciales de Cloudflare dependen de KV para funcionar correctamente.
Fallo en la infraestructura de almacenamiento de terceros
La raíz de la interrupción se relaciona con un proveedor externo: parte del backend de Workers KV depende de infraestructura de almacenamiento de un tercero (tercer proveedor cloud), que también sufrió una caída.
Al fallar esa capa de almacenamiento, Cloudflare no pudo responder correctamente a las peticiones de KV, lo que afectó varios productos integrados.
Impacto en los servicios internos de Cloudflare
Estos son algunos de los componentes que se vieron afectados por el problema en KV:
- WARP: no se podían registrar nuevos clientes y se interrumpió la evaluación de políticas.
- Access y Gateway: problemas en autenticación de sesiones y en la gestión de reglas de seguridad.
- Dashboard de Cloudflare: muchos usuarios no podían iniciar sesión o usar sus sesiones anteriores.
- Challenges / Turnstile: fallaban los procesos de verificación (captchas), lo que también puede bloquear el acceso a aplicaciones que usan esos mecanismos.
- Stream, Workers AI y otros: también sufrieron tasas de error elevadas.
No fue un ataque, pero sí un problema de diseño
Cloudflare ha dejado claro que no se trató de un incidente de seguridad, sino de una falla técnica.
El error demuestra cómo la dependencia en un solo proveedor para infraestructura crítica (como el almacenamiento de KV) puede generar un punto único de falla.
Además, aunque Cloudflare tiene mecanismos de recuperación, durante el incidente algunos de esos “fallbacks” no fueron suficientes para mitigar el impacto total.
Consecuencias para ChatGPT, X y otras plataformas
Interrupción generalizada de servicios
El fallo en la red de Cloudflare provocó una interrupción masiva en plataformas populares, incluyendo ChatGPT y X, entre muchas otras. Muchos usuarios reportaron errores 500 (“Internal Server Error”) al intentar acceder o usar estos servicios. La magnitud del problema fue tal que impactó no solo redes sociales, sino también herramientas de IA y aplicaciones críticas.
Este tipo de caída demuestra lo vulnerable que puede ser una gran parte de Internet cuando un proveedor de infraestructura crítica sufre una falla técnica.
Pérdida de productividad y experiencia del usuario
Para los usuarios de ChatGPT, la caída significó que no pudieron acceder a modelos de IA, interrumpiendo tareas como generación de texto, ayuda en programación o actividades de aprendizaje. En el caso de X, las interrupciones afectaron la comunicación en tiempo real, lo cual puede afectar especialmente a quienes dependen de la red para trabajo, noticias o conexiones profesionales.
Además del daño inmediato, este tipo de fallos erosiona la confianza del usuario. Si alguien intenta usar ChatGPT o X para algo importante y recibe errores repetidos, puede dudar cuándo será seguro o confiable volver a utilizarlos.
Impacto reputacional para las plataformas que dependen de Cloudflare
Las plataformas que dependen de Cloudflare para su operación —como ChatGPT y X— se vieron expuestas a un riesgo reputacional. Cuando una infraestructura tan fundamental como la red de entrega de contenido y seguridad se cae, los usuarios pueden culpar no solo a Cloudflare, sino también a los servicios que quedaron inaccesibles, incluso si esos servicios no son responsables directamente de la caída.
Además, el suceso evidencia una dependencia crítica: muchas aplicaciones confían en redes de terceros para su disponibilidad. Las “Causas del fallo en la red de Cloudflare que impidió usar ChatGPT, X y otros programas” no solo muestran un problema técnico, sino también una debilidad estructural en los modelos de negocio que dependen de infraestructuras ajenas.
Riesgo para desarrolladores y empresas integradas
Más allá de los usuarios finales, el apagón también afectó a desarrolladores y empresas que usan APIs o alojan aplicaciones sobre servicios de Cloudflare. Por ejemplo:
- Si tu app está detrás de Cloudflare, tus usuarios pueden ver errores o no acceder a ciertas funciones durante un incidente.
- Si dependes de autenticación, cachés o reglas configuradas mediante Cloudflare (como Access o Gateways), un fallo puede paralizar flujos de login o autorización.
- En el caso de ChatGPT u otras herramientas de IA que usan infraestructura de Cloudflare, la caída podría haber bloqueado tanto el frontend como las peticiones de backend.
Lecciones para usuarios y empresas
Este apagón subraya varias lecciones clave:
- Diversificación de infraestructuras: depender completamente de un solo proveedor para servicios críticos puede ser arriesgado.
- Planes de contingencia: tanto empresas como desarrolladores deberían tener estrategias para manejar interrupciones en proveedores externos (por ejemplo, cachés locales, fallback de DNS, alternativas de autenticación).
- Comunicación con usuarios: cuando hay un incidente, informar de forma clara y rápida sobre lo que sucede —aunque el problema no sea directamente tuyo, sino de Cloudflare— fortalece la confianza y reduce la frustración.
Lecciones y aprendizajes sobre la dependencia de infraestructuras centralizadas
Reconocer los riesgos de la dependencia de proveedor
Uno de los aprendizajes más claros tras las causas del fallo en la red de Cloudflare que impidió usar ChatGPT, X y otros programas es la amenaza de la dependencia del proveedor (“vendor lock-in”). Cuando muchas aplicaciones críticas dependen de un solo proveedor —en este caso Cloudflare y sus componentes internos como Workers KV— un fallo en ese servicio puede tener un efecto dominó devastador.
Esto demuestra que incluso infraestructuras modernas y distribuidas pueden esconder puntos únicos de falla si no se diseñan con suficiente redundancia.
Mapear y entender todas las dependencias indirectas
No basta con saber qué servicios directos usa tu aplicación: es fundamental identificar las dependencias indirectas, especialmente aquellas gestionadas por terceros. En el incidente de Cloudflare, el almacenamiento subyacente de Workers KV dependía de otro proveedor externo, lo cual no era evidente a simple vista.
Los equipos de DevOps y SRE deben rastrear estas dependencias y documentarlas para evitar sorpresas en momentos críticos.
Diseñar para resiliencia, no solo para rendimiento
Un sistema altamente distribuido no garantiza automáticamente alta resiliencia. Las causas del fallo en la red de Cloudflare que impidió usar ChatGPT, X y otros programas revelan que aunque ciertos componentes parecían descentralizados, existía un “choke point” central: el almacenamiento de KV.
La lección aquí es diseñar arquitecturas con aislamiento de fallos real y caminos de recuperación independientes, en lugar de asumir que “lo distribuido” equivale a “sin riesgo”.
Implementar monitoreo externo e independiente
Durante la interrupción, muchas herramientas de monitoreo no alertaron adecuadamente porque estaban alojadas en la misma plataforma afectada.
Esto subraya la importancia de tener observabilidad externa, es decir, sistemas de alerta y pruebas sintéticas que funcionen desde proveedores distintos para detectar fallos incluso cuando el proveedor principal falla.
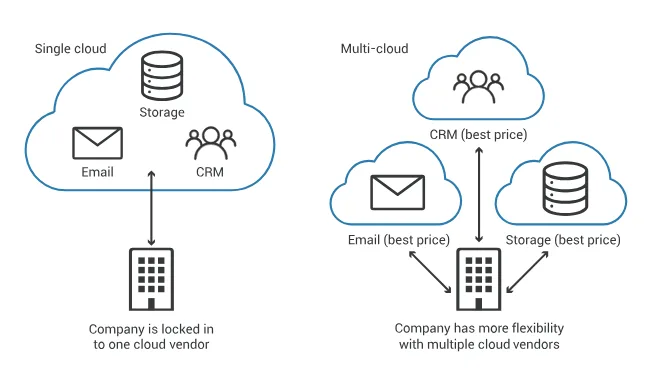
Adoptar estrategias de redundancia y multicloud
Las lecciones extraídas de este incidente también apuntan a la necesidad de estrategias multicloud o híbridas. Confiar solo en un proveedor para servicios críticos incrementa el riesgo: usar múltiples proveedores o tener infraestructura de respaldo puede mitigar el impacto de un fallo centralizado.
Además, es fundamental tener planes de contingencia —como cachés locales, mecanismos de fallback o rutas alternativas de autenticación— que entren en acción cuando el proveedor principal sufra una interrupción.
Comunicar con transparencia y preparar planes de recuperación
Finalmente, un aprendizaje clave no solo es técnico, sino también organizativo. Cuando ocurren incidentes como las causas del fallo en la red de Cloudflare que impidió usar ChatGPT, X y otros programas, comunicar de forma clara y rápida con los usuarios y clientes ayuda a mantener su confianza. También es esencial tener planes de recuperación bien definidos, con equipos entrenados para responder y restaurar servicios lo más pronto posible.

Conclusión
En síntesis, las causas del fallo en la red de Cloudflare que impidió usar ChatGPT, X y otros programas representan una llamada de atención para toda la industria digital. Aunque la interrupción duró poco más de dos horas, dejó claro que incluso los gigantes de la infraestructura en la nube pueden enfrentar interrupciones significativas cuando dependen de servicios externos.
El incidente demuestra que una arquitectura distribuida no es automáticamente sinónimo de resiliencia: cuando un servicio crítico como Workers KV depende de un proveedor tercero, toda una cadena de productos puede colapsar. Para plataformas como ChatGPT o X, este tipo de fallos se tradujo en pérdida de acceso, frustración para los usuarios y un impacto reputacional importante.
Sin embargo, no todo es negativo. De este episodio surgen lecciones muy valiosas: la importancia de mapear todas las dependencias (incluso las “ocultas”), diseñar redundancia real, tener mecanismos de monitoreo externos e implementar planes de recuperación ante fallos. Además, la transparencia al comunicar con usuarios y clientes durante un incidente fortalece la confianza a largo plazo.
Cloudflare también ha reconocido su responsabilidad, y ya ha comenzado a trabajar en mejorar la redundancia de su almacenamiento KV para evitar que una sola dependencia externa vuelva a generar un apagón masivo.


