
La caída mundial de Amazon Web Services del 20 de octubre de 2025 sacudió la infraestructura digital global: miles de sitios web, aplicaciones y servicios dependientes de AWS quedaron inaccesibles, generando caos en empresas, usuarios y ecosistemas digitales. En esta publicación exploraremos qué sucedió, por qué ocurrió, qué empresas resultaron afectadas, cómo AWS actuó para restablecer el servicio y, sobre todo, qué lecciones podemos extraer para prepararnos ante futuras interrupciones en la nube.


Table de Contenido
Qué fue la caída mundial de Amazon Web Services
Panorama general del incidente
La caída mundial de Amazon Web Services fue un evento tecnológico de gran magnitud que ocurrió en octubre de 2025, cuando los servicios de AWS sufrieron fallos masivos que provocaron interrupciones generalizadas en todo el mundo. Muchas plataformas, aplicaciones y sitios web dependientes de la infraestructura en la nube de Amazon dejaron de funcionar temporalmente, lo que evidenció cuán centralizada y crítica es la función que AWS cumple en el ecosistema digital global.
AWS confirmó que, tras varias horas, los servicios regresaron gradualmente a la normalidad, aunque con un volumen importante de mensajes retrasados aún procesándose.

¿Dónde se originó la falla?
El origen del problema fue identificado en la región US-EAST-1, ubicada en Virginia (EE. UU.), que es una de las zonas más usadas por AWS para alojar servicios críticos y bases de datos globales.
En particular, se reportó que el servicio DynamoDB —la base de datos NoSQL gestionada de AWS— presentó un error en la resolución DNS, que desencadenó una reacción en cadena que afectó múltiples servicios dependientes de ese punto de fallo.
Qué sucedió técnicamente
- AWS detectó “error elevado de tasas y latencias” en sus endpoints de DynamoDB en US-EAST-1.
- La falla de DNS implicaba que muchas aplicaciones no podían traducir nombres de dominio a direcciones IP correctas, con lo cual los sistemas no lograban localizar los servidores adecuados.
- Al fallar DynamoDB, otros sistemas que dependían directa o indirectamente de él se vieron afectados, como autenticaciones, cachés, servicios de datos y más.
- AWS descartó que fuera un ciberataque: la causa fue interna, no maliciosa, aunque demuestra hasta qué punto la infraestructura puede ser frágil frente a fallos operativos.

Extensión y duración del impacto
La caída mundial de Amazon Web Services afectó a cientos de servicios y empresas: redes sociales, aplicaciones financieras, plataformas educativas, servicios de streaming, entre otros.
Algunas cifras relevantes:
- Muchas plataformas como Snapchat, Reddit, Fortnite, Zoom, Venmo, Amazon Alexa y más sufrieron interrupciones simultáneas.
- Aunque AWS declaró restaurado el 100 % de sus servicios, reconoció que había un acumulado de mensajes pendientes que requerirían horas adicionales para procesarse completamente.
- La duración del colapso crítico fue de varias horas, con graduales recuperaciones parciales antes de la estabilización total.
Causas detrás de la interrupción global
Problema en la resolución DNS del endpoint DynamoDB
Uno de los factores clave que desencadenó la caída mundial de Amazon Web Services fue un fallo en la resolución DNS del endpoint de la API de DynamoDB en la región US-EAST-1.

En términos sencillos, cuando una aplicación o servicio necesita “hablar” con DynamoDB, debe traducir un nombre de dominio (por ejemplo, dynamodb.us-east-1.amazonaws.com) a una dirección IP mediante DNS. Si esa traducción falla, el servicio queda inaccesible, aunque el sistema backend siga funcionando. AWS mismo reconoció que el problema parecía estar relacionado con ese paso de DNS para DynamoDB.
Este fallo inicial tuvo efectos en cascada, pues otros servicios dependientes de DynamoDB no pudieron operar correctamente, generando errores, latencias elevadas y fallas predeterminadas.
Elevadas tasas de error y latencia en múltiples servicios
Desde los primeros momentos del incidente, AWS reportó “aumentos en las tasas de error y la latencia” para múltiples servicios dentro de US-EAST-1.
Estos errores incluían respuestas HTTP 5XX, timeouts y fallas en la comunicación entre componentes internos. Muchos servicios que parecían estar “aislados” también sufrieron afectaciones porque dependían de ciertos endpoints centrales ubicados en US-EAST-1.
Aunque no se reportaron inicialmente degradaciones en la red pública (es decir, rutas de Internet externas), los problemas internos dentro de la arquitectura de AWS fueron suficientes para desencadenar fallos generalizados.
Interdependencias críticas dentro de la infraestructura
Un aspecto que amplificó el alcance del incidente fue la alta dependencia cruzada entre servicios de AWS. Muchos componentes centrales —como IAM, Global Tables, servicios de control de estado y otros mecanismos administrativos— dependen de recursos o endpoints ubicados en US-EAST-1. Cuando ese punto falla, esos servicios se ven comprometidos también.
Además, algunas operaciones globales de AWS usan rutas o servicios de respaldo que pasan por la región US-EAST-1, lo cual convierte a esta zona en un punto de concentración crítico. Si algo falla allí, muchas operaciones distribuidas se ven afectadas indirectamente.
No se ha reportado un ciberataque — fallo técnico interno
Hasta ahora, no hay evidencia pública de que la caída mundial de Amazon Web Services haya sido causada por un ataque malintencionado o un ciberataque. Los expertos consideran más probable que haya sido un error técnico interno dentro de la infraestructura de AWS.
AWS descartó esta hipótesis en sus primeras comunicaciones, señalando que la causa estaría relacionada con fallos operativos.
Efecto dominó y amplificación del impacto
Lo que empezó como un fallo específico en un componente (DNS → DynamoDB) rápidamente se transformó en un evento de mayor escala debido al efecto dominó:
- Servicios que dependían directamente de DynamoDB fallaron.
- Otros sistemas que interactúan indirectamente con esos servicios también quedaron comprometidos.
- Sistemas globales o administrativas que tenían dependencia en los endpoints centrales dentro de US-EAST-1 sufrieron degradaciones o fallas.
- Mensajes acumulados, colas atrasadas y procesamiento pendiente generaron latencias adicionales incluso después de mitigarse el fallo principal.
Este tipo de amplificación es común en grandes infraestructuras cuando existen dependencias concentradas.
Impacto: qué servicios y empresas se vieron afectados
La caída mundial de Amazon Web Services tuvo un alcance amplio: muchas plataformas, empresas y servicios digitales clave experimentaron interrupciones, fallos o degradaciones. A continuación desgloso los ámbitos principales afectados y ejemplos específicos.
Servicios de Amazon que se vieron comprometidos
No solo empresas externas sufrieron el golpe; varios servicios propios de Amazon también resultaron afectados durante esta caída mundial de Amazon Web Services:
- Amazon.com / sitio de comercio electrónico: usuarios reportaron que no podían acceder al sitio o hacer compras.
- Amazon Alexa / Ring / dispositivos conectados: muchos asistentes de voz y dispositivos IoT dejaron de responder o conectarse.
- Amazon Prime Video / streaming: interrupciones en la reproducción o el acceso a contenido.
- Otros servicios internos de Amazon como procesamiento de backend y funciones dependientes de AWS sufrieron latencia o fallas intermitentes.

Plataformas sociales y de comunicación afectadas
Muchas aplicaciones de interacción social se vieron caídas o con funcionalidad limitada:
- Snapchat fue uno de los más visibles: usuarios reportaron problemas para enviar mensajes o cargar contenido.
- Reddit sufrió fallos de acceso o lentitud incluso cuando otras parts del sistema se recuperaban.
- Aplicaciones de mensajería/colaboración como Slack y Zoom experimentaron intermitencia o fallo de conexión para muchos usuarios durante el pico del incidente.
- Herramientas educativas o de productividad como Canva o Duolingo también reportaron errores o indisponibilidad parcial.
Plataformas de entretenimiento, juegos y streaming
El rubro del ocio digital no estuvo exento del choque:
- Juegos en línea populares como Fortnite y Roblox se vieron interrumpidos para muchos jugadores.
- Servicios de streaming o entretenimiento dependientes de backend en la nube presentaron fallos de carga o interrupciones temporales.
- Plataformas como Twitch o redes de contenido conectadas a la infraestructura de AWS también estuvieron reportadas con degradaciones.
Sector financiero, comercio electrónico y pagos
El golpe fue también fuerte en el mundo fintech:
- Venmo (servicio de pagos P2P) registró fallas de transacción o imposibilidad de realizar pagos mientras duró la caída mundial de Amazon Web Services.
- Plataformas de trading o cripto como Coinbase se vieron afectadas, dificultando operaciones o accesos.
- Grandes empresas del comercio electrónico u otros negocios en línea que dependen de AWS para procesamiento de pagos, autenticación de usuarios o infraestructura backend sufrieron interrupciones operativas.
- Algunas aerolíneas (por ejemplo Delta y United) reportaron dificultades para acceder a sistemas de reservas, check-in y gestión interna de vuelos.
Alcance global y cifras de afectación
Para dimensionar el impacto de la caída mundial de Amazon Web Services:
- Se estima que más de 1,000 empresas y servicios enfrentaron interrupciones o degradación.
- AWS informó que 113 servicios internos se vieron afectados durante el episodio.
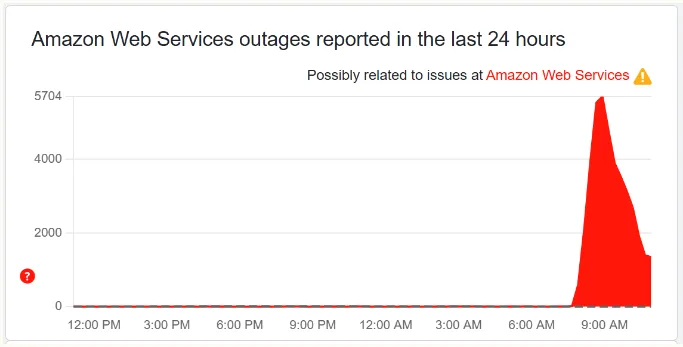
- El sitio Downdetector recogió millones de reportes de fallas (más de 11 millones de quejas en algunos momentos) a nivel mundial.
- La propagación fue global: numerosas regiones en América, Europa y Asia reportaron interrupciones simultáneas en sus servicios digitales dependientes de AWS.
Cómo respondió AWS y cuál fue la cronología de recuperación
Esta sección explora cómo reaccionó Amazon Web Services (AWS) ante la caída mundial de Amazon Web Services, los pasos que tomó para mitigar el daño, y el ritmo con que los servicios fueron restaurados.
Primeros pasos tras el reconocimiento del fallo
Tan pronto como comenzaron los reportes masivos de fallos y latencias, AWS declaró que estaba monitoreando “tasas elevadas de error y latencia” en múltiples servicios, especialmente en la región US-EAST-1.
AWS empezó a emitir actualizaciones a través de su Health Dashboard para clientes, indicando los servicios afectados, el estado de recuperación y los componentes que estaban bajo investigación.
Un paso inmediato que AWS tomó fue limitar el lanzamiento de nuevas instancias o recursos (throttling) mientras estabilizaba la infraestructura, para evitar que nuevos intentos exacerbaran la congestión interna.
Identificación del problema raíz y acciones correctivas
A medida que avanzaba la recuperación, AWS comunicó que la falla central parecía estar relacionada con la resolución DNS del endpoint de DynamoDB en US-EAST-1, lo cual se transformó en el foco principal de corrección.
Los ingenieros de AWS aplicaron mitigaciones en cascada: ajustes en los servidores DNS internos, reconfiguraciones en rutas de red internas y controles en componentes de respaldo.
También involucraron la gestión de colas de mensajes pendientes, ya que muchos servicios tenían acumulados mensajes sin procesar o peticiones fallidas que no se pudieron atender durante el pico del fallo. AWS advirtió que esos “backlogs” (acumulaciones) podrían tardar varias horas adicionales en procesarse completamente, incluso después de la mitigación del error principal.
Cronología estimada de recuperación
El análisis público indica la siguiente línea de tiempo aproximada para la recuperación de la caída mundial de Amazon Web Services:
- ≈ 09:22 UTC: comenzaron evidencias de recuperación en algunos servicios clave.
- ≈ 09:35 UTC: se registró que el problema principal comenzaba a ceder y la mayoría de las peticiones críticas empezaban a resolverse.
- Durante el día, AWS continuó estabilizando servicios, escalando correcciones y procesando los backlogs de mensajes.
- ≈ 18:01 ET (tarde del día, hora de EE. UU.): AWS declaró que “todos los servicios retornaron a operaciones normales”.
- Aun así, cierto nivel de procesamiento residual, ajustes internos y normalización continuaron horas después de esa declaración oficial.
Comunicación con clientes y transparencia
AWS mantuvo actualizaciones constantes en su página de estado (Health Dashboard), indicando progresos, servicios que iban recuperando y alertas de posibles latencias residuales.
En sus comunicados públicos, AWS reconoció que algunos servicios aún podrían experimentar throttling (limitaciones voluntarias) mientras se terminaban de procesar los backlogs.
También pidió a los clientes que reintenten operaciones fallidas conforme los sistemas se estabilizaban y evitara “rechazos masivos” de peticiones que podrían generar aún más congestión interna.
Estado final y lecciones inmediatas
Para el final del día, AWS pudo afirmar que el servicio estaba nuevamente operativo en su totalidad, aunque con advertencias de que algunos clientes podrían notar efectos residuales menores.
La respuesta de AWS mostró su capacidad de acción ante emergencias en su infraestructura, aunque el incidente también revela cuán vulnerable puede ser un sistema tan interconectado.
Lecciones aprendidas y riesgos de centralización en la nube
La caída mundial de Amazon Web Services ha dejado claro que incluso los gigantes tecnológicos no están exentos de fallos operativos. Este incidente ofrece lecciones valiosas para organizaciones, desarrolladores y responsables de TI, especialmente en lo que respecta al riesgo de depender fuertemente de una única infraestructura en la nube. A continuación, se detallan los aprendizajes clave.

Diversificación de regiones y proveedores
Una de las principales lecciones de la caída mundial de Amazon Web Services es que tener todos los recursos concentrados en una sola región o un solo proveedor puede incrementar significativamente el riesgo de interrupción.
Para mitigar este riesgo:
- Desplegar servicios críticos en múltiples regiones geográficas, de modo que la falla de una región (como lo fue US-EAST-1 en este caso) no paralice toda la operación.
- Considerar la estrategia de múltiples proveedores de nube (multi-cloud) o nube híbrida, aunque reconociendo que implica complejidad operativa.
Arquitectura preparada para fallos (design for failure)
La caída mundial de Amazon Web Services muestra que incluso infraestructuras muy robustas pueden fallar cuando un componente central colapsa. Es por ello que diseñar para fallos es clave:
- Preparar sistemas para degradación inteligente: aunque no se mantenga el 100 % de funcionalidad, que el sistema ofrezca un servicio reducido en lugar de una caída total.
- Implementar mecanismos de fail-over automáticos, cachés locales, colas pendientes, y replicación cruzada de datos.
Visibilidad, monitoreo y pruebas de resiliencia
Otro aprendizaje importante es que no basta con dependiendo del proveedor de nube para la disponibilidad: las organizaciones deben tener visibilidad propia, monitoreo efectivo y ensayar escenarios de falla.
- Configurar alertas tempranas a través de dashboards de salud del proveedor y de herramientas de terceros.
- Realizar simulacros de recuperación ante desastre, pruebas de conmutación por error (failover), y ejercicios de contingencia para verificar que los planes funcionan.
Entender el riesgo de puntos únicos de fallo y centralización
La caída mundial de Amazon Web Services revela de forma contundente cómo la centralización de servicios —por ejemplo, una región crítica, un servicio de DNS compartido, un plano de control global— puede convertirse en un punto de vulnerabilidad masiva.
- Identificar componentes críticos que podrían convertirse en “cuellos de botella” o fallos en cadena.
- Diseñar para minimizar el “blast radius” (radio de daño) de una falla: es decir, que aunque falle un componente, el impacto sea contenido y no se propague masivamente.
Riesgos organizacionales y de negocio más allá de la tecnología
La tecnología es solamente una parte del riesgo. La caída mundial de Amazon Web Services también nos enseña que los impactos organizacionales, de reputación y de negocio pueden ser graves:
- Pérdidas económicas debido a interrupciones de servicio, transacciones fallidas o clientes insatisfechos.
- Necesidad de planes de comunicación claros: cuando ocurre una interrupción, los clientes esperan respuestas, transparencia y acciones.
- Revisión de contratos, acuerdos de nivel de servicio (SLA) y costes ocultos de recuperación: a veces, depender de un solo proveedor sin plan de contingencia puede ser más costoso que parece.

Cómo prepararse frente a futuras caídas en servicios en la nube
Ante la posibilidad de otra caída mundial de Amazon Web Services o fallos similares en otras plataformas de nube, es esencial que las organizaciones adopten estrategias preventivas y planes claros de recuperación. A continuación se presentan recomendaciones clave para fortalecer la resiliencia frente a interrupciones en la nube.
Definir objetivos de recuperación: RTO y RPO claros
Un primer paso fundamental es establecer objetivos de recuperación realistas:
- RTO (Recovery Time Objective): cuánto tiempo puedes permitir que el servicio esté fuera de operación antes de que el impacto sea inaceptable.
- RPO (Recovery Point Objective): cuánto dato puedes permitir perder; es decir, hasta qué punto aceptas que los datos no se guarden.
Tener estos objetivos claros permite diseñar estrategias de respaldo y recuperación adaptadas al nivel de riesgo que la empresa puede tolerar.
Aplicar estrategias de recuperación distribuidas (DR)
AWS documenta varias estrategias de recuperación ante desastres (DR) desde enfoques simples hasta arquitecturas complejas.
Algunas de las más comunes:
- Backup y restauración: respaldar datos y configuraciones, y restaurarlos en otra región o ambiente cuando sea necesario.
- Pilot light: mantener una versión mínima activa en otra región que pueda ampliarse rápidamente en caso de falla.
- Warm standby: tener instancias ya activas pero de menor capacidad que puedan escalar rápidamente.
- Multi-site (activo-activo): operar en paralelo en dos o más regiones, balanceando carga y permitiendo conmutaciones automáticas.
Al usar estas arquitecturas, el impacto de una caída mundial de Amazon Web Services u otro fallo localizado puede minimizarse.
Adoptar una estrategia multi-cloud o híbrida
Para no depender exclusivamente de un solo proveedor, considera:
- Multi-cloud: repartir cargas críticas entre AWS, Azure, GCP u otros. En caso de falla en AWS, parte del sistema puede seguir operativo en otro proveedor.
- Nube híbrida (on-premise + nube): mantener componentes críticos localmente o en infraestructura privada que actúen como respaldo.
Estas estrategias agregan complejidad operativa, pero ofrecen una barrera más ante interrupciones masivas. N2WS recomienda el uso de multi-cloud o soluciones híbridas como parte de una estrategia de supervivencia frente a fallos severos.
Automatización, infraestructura como código (IaC) y “pruebas de caos”
Poder replicar, escalar o recuperar infraestructuras de forma automatizada es esencial:
- Gestionar toda la infraestructura mediante IaC (Terraform, CloudFormation, CDK), de modo que puedas desplegar o restaurar entornos con scripts en lugar de operaciones manuales.
- Automatizar snapshots, backups, pruebas de restauración y conmutaciones por error (failover).
- Realizar simulacros de fallo o pruebas de caos (chaos engineering) para verificar que los mecanismos de recuperación funcionan ante escenarios impredecibles.
Estas prácticas ayudan a que la reacción ante una caída mundial de Amazon Web Services sea rápida, confiable y menos dependiente de acciones manuales.
Monitoreo, alertas y visibilidad externa
Contar con visibilidad y alertas tempranas es clave:
- Usar herramientas que monitoreen la salud de los servicios de nube (dashboard de AWS, status APIs) así como métricas de latencia, error y dependencia.
- Configurar alertas que detecten anomalías antes de que el servicio colapse.
- Incorporar monitoreo de dependencias cruzadas para entender qué servicio depende de cuál, y cómo un fallo puede propagarse.
Un artículo reciente subraya que muchas organizaciones descubrieron demasiado tarde que sus cargas clave estaban concentradas en la región más afectada (us-east-1), lo que resalta la importancia de tener visibilidad completa de tus recursos.
Plan de comunicación y recuperación organizacional
La preparación no es solo técnica:
- Tener un plan de comunicación claro para clientes, usuarios y partes interesadas: informar sobre la incidencia, qué se está haciendo, tiempo estimado de recuperación, etc.
- Definir roles y permisos antes: quién puede activar el plan de recuperación, quién autoriza conmutaciones, etc.
- Ensayar el plan de gestión de crisis y retroalimentar lecciones aprendidas tras cada simulacro.
Una comunicación transparente puede mitigar el daño de reputación cuando se produce una caída mundial de Amazon Web Services.
Estimar costos y mantener respaldo económico
Prepararse tiene costos, pero no hacerlo puede ser más caro:
- Considerar los costos adicionales de replicación, infraestructura inactiva en standby, transferencia de datos entre regiones o proveedores.
- Hacer un análisis costo-beneficio: cuánto perderías por hora de interrupción frente al gasto para tener una arquitectura resiliente.
- Reservar recursos financieros para emergencias tecnológicas, pruebas y actualizaciones.
Conclusión
La caída mundial de Amazon Web Services del 20 de octubre de 2025 no fue simplemente un fallo técnico más: fue un recordatorio contundente de cuán interconectada y frágil puede ser la infraestructura digital moderna. Aunque AWS logró restaurar sus servicios en el transcurso del día, los efectos resonaron en todo el ecosistema tecnológico —empresas, usuarios, servicios críticos— dejando lecciones que no deben pasarse por alto.

No se trata solo de tecnología, sino de confianza
Cuando una plataforma tan fundamental como AWS falla, el daño no es solo técnico: es reputacional. Muchas empresas que dependen de la nube deben responder no solo con correcciones técnicas, sino con transparencia ante sus usuarios, explicando qué ocurrió y cómo se evitará en el futuro.
Prepararse es una obligación, no una opción
Este incidente confirma que ningún proveedor es inmune a fallos. Diseñar para la resiliencia —distribuir cargas, hacer pruebas de falla, automatizar recuperaciones, tener planes alternativos— debe formar parte del ADN de cualquier estrategia de infraestructura en la nube.
La centralización sigue siendo un riesgo latente
Concentrar recursos críticos en una sola región, servicio o proveedor sigue siendo una debilidad estratégica. La caída mundial de Amazon Web Services demostró cómo una falla localizada puede propagarse rápidamente, afectando servicios, economías y experiencias digitales en todo el planeta.
Mirando hacia adelante: resiliencia consciente en la nube
La nube seguirá siendo el pilar de la innovación digital, pero su uso responsable exige prudencia técnica y estratégica. Los equipos deben anticiparse al error, construir mecanismos de contención y diversificar su arquitectura. Solo así podrán enfrentar eventos extremos sin parálisis.


